Apache Cassandra is a popular column oriented NoSQL database which was originally developed at Facebook and is influenced by Googles Bigtable and Amazons Dynamo DB. It is focused primarily on high availability, fault tolerance and scalability. It is often used in Big Data settings and supports up to 2 billion cells (rows * columns) per partition. One of the largest production installation consists of over 75,000 nodes with in total more that 10 Petabyte (1 Petabyte = 1000000000000000 byte = 1015 bytes) of stored data.
The data model of Apache Cassandra can be visualized as shown in the following figure. It consists of the main parts Key Space, Column Family, Row and Column. Furthermore, Cassandra is usually used as a cluster of multiple nodes. Due to its internal architecture, Cassandra can efficiently and reliably distribute data across the nodes in a cluster.
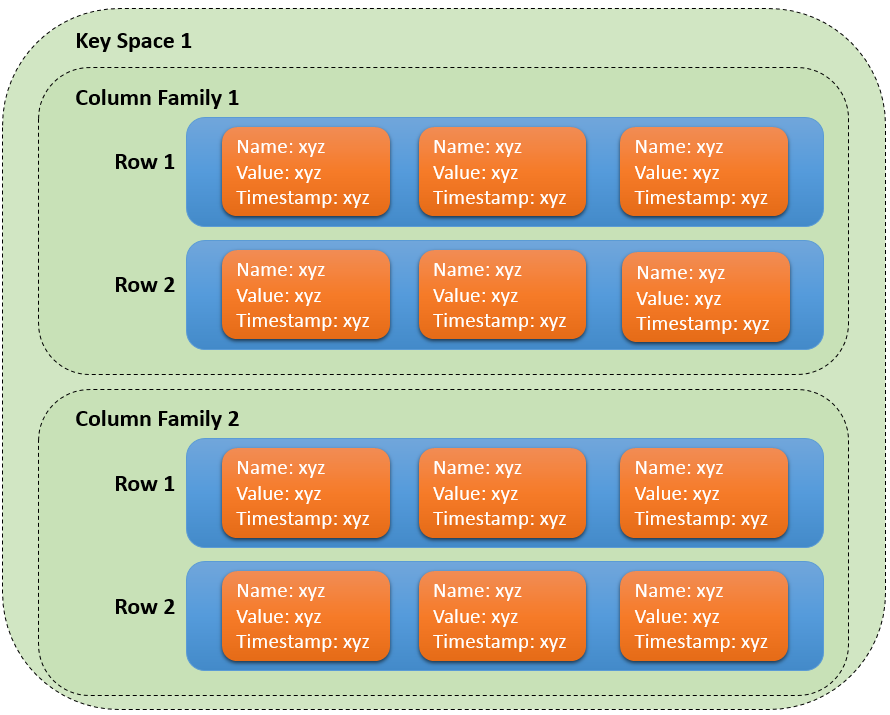
Each column consists of a triple: (name, value, timestamp). A column is the basic building block of the Cassandra data model. In contrast to a Relational Database Management System (RDBMS), data can also be stored in a column name (maximum amount is 64KB for the name and 2GB for the column value). A column can also have a Time-To-Live (TTL). After the TTL has expired the entry is deleted asynchronously.
Furthermore, Cassandra defines the concept of Super Columns. Super Columns are columns that themselves consist of a set of columns.
A row is an ordered set of columns. Cassandra sorts the columns in a row based on their names. In contrast to a RDBMS, each row can have different columns.
A column family is a set of rows. Each column family must define a primary key that can consist of a single column or of a composite of multiple columns. The primary key is used to determine the storage location for the row. The columns of a row are never split across several Casandra nodes.
A key space is a set of column families. It resembles the concept of a database or schema in the relational world.
A Cassandra Cluster consists of multiple nodes. The data stored in Cassandra is distributed across those nodes using its primary key. Cassandra supports linear scaling by adding further nodes to the cluster.
Cassandra comes with its own SQL like language, the Cassandra Query Language (CQL). It can be used to CREATE tables and to SELECT, UPDATE, INSERT or DELETE data. Cassandra does not support joins, so neither does CQL. You can restrict your queries’ result set by using WHERE on columns that are indexed. But there are no sub-queries or GROUP BY expressions. Especially the lack of joins has to be considered when creating a data model. If you need a join in your application you have to either de-normalize your schema upfront or to do the join in your application manually. The latter can easily be too expensive for large data sets.
Furthermore, Cassandra does not support ACID transactions. Instead of atomic operations there are idempotent operations. This means, that regardless how often an idempotent operation is executed, it leaves the system in the same state. However, if e.g. a write operation fails, there can be partially written data left. The same cannot happen within a RDBMS.
Spring Boot greatly simplifies the amount of setup work needed to access Cassandra from Java.
For the basic setup we need some dependencies. To get started, we use the following Gradle build script:
apply plugin: "java"
apply plugin: "eclipse"
sourceCompatibility = 1.8
version = "1.0"
buildscript {
repositories {
jcenter()
}
dependencies {
classpath("org.springframework.boot:spring-boot-gradle-plugin:1.3.3.RELEASE")
}
}
apply plugin: "spring-boot"
repositories {
jcenter()
}
dependencies {
compile "org.springframework.boot:spring-boot-starter-data-cassandra:1.3.3.RELEASE"
testCompile "junit:junit:4.12"
testCompile "org.springframework.boot:spring-boot-starter-test:1.3.3.RELEASE"
}After that it’s time to configure the Cassandra instance. For testing purposes, you can e.g. set-up Cassandra in a docker container. Furthermore, we need to provide an application.properties configuration:
spring.data.cassandra.contact-points=localhost
spring.data.cassandra.keyspace-name=trinnovative
spring.data.cassandra.port=9042Please don’t forget to replace contact-points and port with your actual configuration.
After that we can create a new Key Space. This can be done by using your favorite DB tool (for example DBeaver).
CREATE KEYSPACE IF NOT EXISTS trinnovative WITH REPLICATION = { 'class' : 'SimpleStrategy', 'replication_factor' : 1 };
USE trinnovative;
CREATE TABLE person (
id timeuuid PRIMARY KEY,
fname text,
lname text
);
CREATE INDEX IDX_PERSON_LNAME ON person (lname);Now it’s time to create our (very simple) database model. We use a base class to abstract away the primary key generation. For the primary key, we use a version 1 (time based) UUID as provided by the Cassandra datastax driver.
package de.trinnovative.blog.cassandra;
import java.util.UUID;
import org.springframework.data.cassandra.mapping.PrimaryKey;
import com.datastax.driver.core.utils.UUIDs;
public abstract class AbstractEntity {
@PrimaryKey("id")
protected UUID id;
public AbstractEntity() {
this.id = UUIDs.timeBased();
}
public UUID getId() {
return id;
}
}Furthermore, we create an example entity called Person that has the properties firstname and lastname.
package de.trinnovative.blog.cassandra;
import org.springframework.data.cassandra.mapping.Column;
import org.springframework.data.cassandra.mapping.Table;
@Table(value = "person")
public class Person extends AbstractEntity {
@Column("fname")
private String firstname;
@Column("lname")
private String lastname;
public Person(String firstname, String lastname) {
this.firstname = firstname;
this.lastname = lastname;
}
@Override
public String toString() {
return Person.class.getSimpleName() + "[id='" + id + "', firstname='" + firstname
+ "', lastname='" + lastname + "']";
}
}To be able to do basic CRUD operations we also create a Spring Data repository. Please note, that we can only query by lastname because we’ve created an index on that column beforehand. If there is no such index, an exception will be thrown instead.
package de.trinnovative.blog.cassandra;
import java.util.List;
import java.util.UUID;
import org.springframework.data.cassandra.repository.Query;
import org.springframework.data.repository.CrudRepository;
public interface PersonRepository extends CrudRepository<Person, UUID>{
@Query("SELECT * FROM Person where lname = ?0")
List<Person> findByLastname(String lastname);
}We can now start saving and querying data with Cassandra:
Person tom = new Person("tom", "bauer");
tom = repository.save(tom);
Person person = repository.findByLastname(tom.getLastname()).get(0);
System.out.println(person);Which prints:
Person[id='2ae1fe80-ed18-11e5-ab58-9d5fc550e57e', firstname='tom', lastname='bauer']In this article we’ve seen some basic properties of the Apache Cassandra database. It’s main advantages are high availability, fault tolerance and scalability. We’ve seen that those properties come with a cost. When designing our application we have to take into account that there are no ACID transactions and no joins.
Last but not least, we’ve seen that it’s pretty easy to prepare a basic CRUD setup for Cassandra with Spring Boot and Spring Data.
Wir möchten Cookies und Skripte von Dritten verwenden, um die Funktionalität dieser Website zu verbessern.

